


by Tzlil Sharon, translation Sondra Turjeman
A one of a kind course – a meeting between biology and coding – was granted another teaching assistant this year through support of the Data Science Center. This small addition made a big change. For the first time, Professor Michal Linial saw her vision become a reality when 25 advanced degree students that did not have a formal background in computer sciences, learned to stop worrying and love the big data.
Three years ago, when Professor Michal Lanial decided to develop a Quantitative Biological Research with Python course, she discovered that a dual challenge lay ahead of her. Not only is development of a new course a large administrative undertaking, but in this case, there was a unique need for initiative and creative thinking on how to combine two separate research worlds. How could the gap between the lab work of biology, something not taught in computer sciences, and big data, now available in endless databases, be bridged? “The understanding that something needed to be done just wasn’t there yet.”, Linial states. “I had countless conversations with departments heads in the Institute of Life Sciences and I couldn’t convey the understanding that this is a course that needs investment beyond a typical course.”
Prof. Linial, who studies the relations between individuals’ genomes and biological trends such as obesity, depression, and aging, sees herself as a “translator. As the founder of the Computational Biology program at the Hebrew University two decades ago, Linial knows the difficulties of translating the language of “classical biology” into “computer talk” intimately. While classical biology describes problems and phenomena in words, the language of computers is based on technical procedures and statistical calculations which allows for exposing patterns in a sea of raw data collected in labs.
“Once there was one gene, one lab, one researcher. That era has passed,” Linial explains. “Today, we know that there are more than 20,000 genes in the human genome, but in order to understand these 20,000 genets, we must understand what happens in genomes of thousands of other organisms in our environment. If we do not know what the analog of a human disease is in a mouse, a worm, or any other model organism, we can continue talking about and describing the disease, but that in itself won’t drive us to research and discovery.”
In other words, analysis methods developed by computer scientists in the last century have allowed biologists to research more than tens of thousands of genes at a time instead of working gene-by-gene. Once biologists are not dependent upon experimental findings alone, a whole new set of research opportunities and questions becomes available. Linial’s research provides a plethora of examples, one of which is connected to viruses. “I was curious to learn whether viruses steal our DNA in order to improve themselves. It is actually a question of information theft, one that concerns data. There can be two scenarios: either the virus gives, or the virus takes. How can we differentiate between them? We built a computational model that says: if there has been a theft, then the gene should only be present in the virus; if it was given, then we should expect to find it in both the host genome and the virus genome. We then asked, which scenario is more likely? We found that viruses, known to be givers, in practice, also steal. With a bit of
editing, they turn out incredibly successful.”
How did you find these people?
The initiative to bring this data-driven approach to young biologists without a background in computer sciences was sparked by a conversation with Nadav Brandes, a PhD student supervised jointly by Linial and her husband, Professor Nathan Linial, from the School of Engineering and Computer Sciences. “Nadav was convinced that biologists should be forced to make the jump”, she recalls. “He told me, let’s take graduate students that realize that they have to be able to ‘formalize’ a problem and also enjoy the fact that there are tons of data all around them. People that already know everything about research but don’t have the skills.
It is like running a marathon with weights on one’s feet. One understands that if one didn’t have the weights on, one would truly be able to run. These are the types of people we wanted.”
How did you find these people?
“We decided to do something a bit audacious, administratively. First, in order to give representation to multiple labs, if there were multiple applicants from the same lab, we would take at least one. Second, we wanted people who had no background in computer sciences but had already taken Python courses I and II. In other words, we wanted students that really understood that a course like this was a fundamental requisite to furthering their research, even if they couldn’t yet visualize it. Additionally, we made it clear to them that this is a course like they have never seen before in terms of workload. If students didn’t have two days a week to invest in it, this wasn’t the course for them. Those who stuck it out – we knew they meant business. The problem was that in the last two years, we didn’t do such strict filtering and therefore had a high level of dropout.”
HWhat is the difference between this year’s course format and that of previous years?
“In the past, we felt like we were missing something: The students had the will, we had the will, the investment on both sides was huge, and yet we didn’t know how to lift it off the ground it. Believe me, I had dozens of conversations with department heads in the Life Sciences that were great, but nobody understood the true meaning of developing a tailor-made course that would suit this particular need, one that would specifically complement the work of biologists, not just a regular extra-curricular course. An essential course. In my despair, so to speak, I turned to Dr. Dafna Shahaf form the School of Computer Sciences and Engineering, and Dr. Yuval Benjamini from the Statistics Department (heads of the Hebrew University Data Science Center) because I knew that they were working on similar initiatives. It was amazing because they immediately understood the need. It made a huge difference.”
In what ways were the changes manifested?
“The support of the Data Science Center allowed us to add an extra TA to the course, a charming student named Vladimir Gritsenko. In the past, we had a waiting list of 50 students, and we were limited to less than 20 because we needed to check their exercises each week and guide them through the flood of work that each exercise entailed. When Vlad joined, we were able to take 26 students. All but one completed the course successfully. For comparison, last year, we took 18 students and only 12 finished because we were unable to adequately support everyone. For a lot of people, the course was too hard, and they never got that individual push they needed.”
The course, worth five credit hours, demands unprecedented student investment. “The course is taught in English and it is intended to be for PhD students”, explains Linial. According to her, it contains a full day of learning, from 10am to 4pm, and then another full day, dedicated to ‘homework’. As a result, she says that a special intimacy between participants is fostered. “It’s an intimacy that is generated, among other things, from burden, from the load of assignments. The students begin to work on an assignment in class, and Vlad and Nadav (the second TA) float between them, helping each student as needed, and in the last fifteen minutes of class, students get a hint for their homework assignment. So there they are, sitting together, attentive, working closely with the TAs and with one another to the point where, at 4pm, I literally find myself telling them ‘Enough, go home!’. But the students understand that there is an advantage to being a part of this group.”
It sounds like group dynamics are the key to the course’s success.
“Definitely. It is a way of learning that is both very intensive and also very personal. Every time a problem arises, we discuss it, and one of the students offers a solution. It’s sort of similar to – well I wouldn’t say a high-tech company, but like it is a group task, even though [each assignment] is individual. For example, one week was dedicated to the question of ‘What do you do when you receive a faulty code?’ Who heard of such a thing, a biologist who knows how to troubleshoot a code? You don’t understand what is written in the code; you have no idea to which database to turn. It ended up being a group-wide treasure hunt. Together the students had to determine which data to access, where the problems were, and how to fix the code. They ended up making a WhatsApp group in order to discuss between themselves and with their TAs.”
In addition to the lessons, which deal with proteins, viruses, diseases, practical statistics and getting to know the data science toolset, Linial points out that the course’s uniqueness comes from the fact that it teaches the students how to launch a research project in the world outside of the classroom. “At the end of the semester, they must give a pre-proposal to explain this project, including which data they will use, from where it will come, and what research questions will be answered. It is a simulation of how to write a research proposal in order to receive research grants, and we sit and discuss if we should approve the proposals,” Linial details.
After this, the students are divided into groups and they develop their initial proposals into larger-scale projects that they are required to present the following semester. “Each project must have a statistical element, a visual element, a parsing element, and a coding element. We are talking about interesting, scientific, really unique projects”, Linial enthusiastically explains, and gives a few examples: “How to create a database for doctors that is more accessible; how we can see the rate of development of proteins associated with disease; what in the genome of a plant enables it to deal with drought.” The overall goal of Linial’s approach is to develop independent research skills in students, inspired by the sharing-driven approach of the computer sciences community. “For me, it has been truly eye-opening because I never thought of a course as a platform for problem solving,” she acknowledges.
To summarize, we spoke a lot about what data science gives to biologists. What do you think biologists have to offer to data science?
“I believe that a good biologistdevelops what I call a ‘biological intuition’. This intuition doesn’t exist unless one has worked in a lab and become familiar with the data up close, that is, only if one had to go and extract the data on one’s own. In this respect, I think that biologists bring to the table an unmediated engagement with reality, which is very important. Essentially, if you don’t speak with a doctor or a biologist, you haven’t done much. You can do some sort of clever data analysis and it can be published in a book of clever analyses, but in truth, it all comes down to working together as a community.”
Original interview excerpts have been translated from Hebrew.

Infer, filter and enhance topological signals in single-cell data using spectral template matching
Single-cell RNA sequencing is a powerful technology that allows researchers to analyze gene expression in individual cells, providing insights into cellular processes and functions. However, analyzing this data can be challenging, as cells can simultaneously encode multiple, potentially cross-interfering, biological signals. A new computational method, scPrisma, was developed to address this challenge. scPrisma has the ability to uncover cellular spatiotemporal context and has the potential to drive further insights into cellular processes and functions, ultimately advancing our understanding of biology.

התנהגות שיחור מזון חברתית – מעבדת האקולוגיה של התנועה של פרופ' רן נתן
עטלף הפירות המצרי משחק תפקיד מפתח בהפצת זרעים של מגוון צמחים, לרבות מינים פולשניים. עטלפי פירות ידועים בתור מין חברתי ביותר, אולם דפוסי שיחור המזון שלהם נותרו עד היום בגדר תעלומה, וכך גם ההתנהגויות החברתיות הנלוות לאותם דפוסים. חוקרים מקווים לשנות את כל זה באמצעות שימוש במכשירים איתור-מיקום ממוזערים ברזולוציה גובהה, שהוצמדו לאוכלוסיית עטלפים גדולה (כמעט מושבה שלמה) לצורך איסוף נתונים מדויקים על הרגלי התעופה, ההפצה והניווט שלהם. ניתוח הנתונים בראי תורת הגרפים יאפשר, כך מאמינים החוקרים, לחשוף את הרשת החברתית הפועלת מאחורי ההתנהגות המסתורית של העטלפים ולהגיע לתובנות משמעותיות שלא היו נגישות עד כה. כדי לדעת עוד, המשיכו לקרוא או בקרו באתר המעבדה ל אקולוגיה של התנועה (אנגלית).
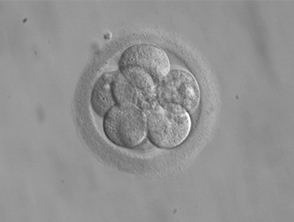
הפריה חוץ־גופית: הערכת איכות עוברים לפני החזרתם לרחם – מעבדת בוקסבוים למכאנוביולוגיה תאית וביופיסיקה של תאי גזע וגרעינים
לפחות אחד מתוך 25 תינוקות בישראל הוא תינוק מבחנה, אך עדיין אין ברשותנו אמצעים מדויקים להערכת איכות העובר טרם השתלת הביצית המופרית ברחם. לכן, מקובל להשתיל מספר עוברים על מנת להגדיל את סיכויי לקליטת היריון מוצלח, אולם כתוצאה מכך גדל גם הסיכוי להריון מרובה עוברים. מטרת הפרויקט הנוכחי היא לצפות מראש לאילו עוברים הסיכוי הטוב ביותר להוביל להריון מוצלח עוד בטרם השתלתם ברחם, באמצעות ניתוח מאגר נתונים של למעלה מ-70,000 עוברים. למידע נוסף, המשיכו לקרוא כאן, או בקרו באתר מעבדת בוקסבוים ובמאגר Nanshe Database.