


by Sondra Turjeman
In a quick Google search of “job trends 2019” the same things keep popping up: data science, python, and (re-)training opportunities. Even in the most people-oriented jobs, data management and analytics are becoming more prevalent. In the digital age, data can very easily be generated, often times without considering to what end. As companies big and small begin to accumulate large amounts of data, from customer satisfaction to product performance to shipping logistics to genetic make-up, job descriptions are shifting to include data-based skills.
This trend isn’t only obvious in the job market. Throughout the education system, we see more and more coding classes and extra-curricular activities with a greater emphasis on computer sciences. Furthermore, enrollment in “big-data” related degrees including computer science, bioinformatics, statistics, and quantitative marketing are also on the rise. But even beyond big-data fields, we see an ever-increasing need for code-savvy students. Ecologists have troves of movement data, neuroscientists have detailed brain-maps, medical professionals have endless data from both healthy and sick patients, and natural language processing (NLP) is now being used in a number of fields including law, linguistics, and business.
With a hot job market, it is often difficult for researchers to find a data scientist to help in data-handling and analyses. AI and machine learning, both seemingly abstract, are being thrown around regularly across disciplines, but even as models appear to be increasingly more complicated, tools abound, and coding is within hand’s reach for students, researchers and workers regardless of field or background. Just like learning anything new, it takes a bit of practice, but resources are readily available, and opportunities for learning and improvement are endless. In just a few hours with minimal experience, a new user can perform basic data exploration tasks and begin to see the investment pay off.
Getting Started in Data Science
But with so many options, how do you start? First let’s define data science. As defined on Wikipedia, it is “a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data.” Data science is performed in a computer programming environment. Different environments use different languages (e.g. C, C++, java, R, Ruby on Rails), and while the principles of coding are shared across platforms, each language has its own nuances and strengths. Currently Python is a great starting point; it is relatively easy to use and popular among academics and industries alike. It is versatile and very user-friendly with thoroughly documented libraries (available codes written by other users) and a strong user community.
In many cases, there isn’t a perfect coding course for exactly what you need. But in even more cases, you don’t really need that perfect course. A basic introduction to your chosen language is often enough to get you started and familiar with the coding environment. There are short boot-camps and longer courses available online for a variety of platforms. In no particular order, here are just a few recommendations for getting acquainted for Python: YouTube: Python Tutorial for Beginners; Google for Education: Google’s Python Class; Codecademy: Learn Python 2; DataCamp: Introduction to Python; Coursera: Python for Data Science and AI. There are also basic, department-specific university courses to get you started (HUJI Python courses: Cognitive Science: 06130, Social Sciences: 54260, Life Sciences: 76631, 76632, Earth Sciences: 76634, Mathematics: 76637, Biomedicine: 76638, Physics 76639, Agriculture: 71137, Geography: 40358) or that focus on more advanced tasks (object oriented: 06141, quantitative biology: 92847, NLP: 67658, 67583).
The best way to learn, though, is to just jump in. By beginning to code and becoming more experienced in thinking like a computer, you will quickly pick up many nuances of coding. For specific data processing and analysis tools, open-source toolboxes, packages, or libraries are typically available and accompanying documentation is often highly detailed and accessible even for those without strong mathematical and statistical backgrounds. In addition, many universities have student coding groups or forums in which you can get a little bit of extra help, and there are great global community initiatives and challenges like Tidy Tuesday (for R) and PyBites and CodeWars (for Python) If you are still stuck, there are a number of online forums on which you can find answers to pressing questions you may have or that others have asked before you (e.g. StackExchange, ResearchGate, PythonForum).The Center has also brought to life an in-person, MOOC-driven course (massive open online courses; 67876) to support students who need that extra push in their independent learning journey.
While many of us did not formally study computer sciences or data science, there is no reason we should be excluded from the big data revolution taking the industry and academia by storm. With a bit of time and a willingness to make mistakes and get your hands dirty, even the most daunting projects can become accessible. For help getting started, CIDR is here to offer workshops, support in MOOCs, and mentorship. We wish you the best of luck on your data science journey.

Infer, filter and enhance topological signals in single-cell data using spectral template matching
Single-cell RNA sequencing is a powerful technology that allows researchers to analyze gene expression in individual cells, providing insights into cellular processes and functions. However, analyzing this data can be challenging, as cells can simultaneously encode multiple, potentially cross-interfering, biological signals. A new computational method, scPrisma, was developed to address this challenge. scPrisma has the ability to uncover cellular spatiotemporal context and has the potential to drive further insights into cellular processes and functions, ultimately advancing our understanding of biology.

התנהגות שיחור מזון חברתית – מעבדת האקולוגיה של התנועה של פרופ' רן נתן
עטלף הפירות המצרי משחק תפקיד מפתח בהפצת זרעים של מגוון צמחים, לרבות מינים פולשניים. עטלפי פירות ידועים בתור מין חברתי ביותר, אולם דפוסי שיחור המזון שלהם נותרו עד היום בגדר תעלומה, וכך גם ההתנהגויות החברתיות הנלוות לאותם דפוסים. חוקרים מקווים לשנות את כל זה באמצעות שימוש במכשירים איתור-מיקום ממוזערים ברזולוציה גובהה, שהוצמדו לאוכלוסיית עטלפים גדולה (כמעט מושבה שלמה) לצורך איסוף נתונים מדויקים על הרגלי התעופה, ההפצה והניווט שלהם. ניתוח הנתונים בראי תורת הגרפים יאפשר, כך מאמינים החוקרים, לחשוף את הרשת החברתית הפועלת מאחורי ההתנהגות המסתורית של העטלפים ולהגיע לתובנות משמעותיות שלא היו נגישות עד כה. כדי לדעת עוד, המשיכו לקרוא או בקרו באתר המעבדה ל אקולוגיה של התנועה (אנגלית).
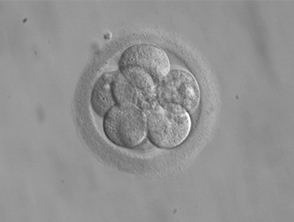
הפריה חוץ־גופית: הערכת איכות עוברים לפני החזרתם לרחם – מעבדת בוקסבוים למכאנוביולוגיה תאית וביופיסיקה של תאי גזע וגרעינים
לפחות אחד מתוך 25 תינוקות בישראל הוא תינוק מבחנה, אך עדיין אין ברשותנו אמצעים מדויקים להערכת איכות העובר טרם השתלת הביצית המופרית ברחם. לכן, מקובל להשתיל מספר עוברים על מנת להגדיל את סיכויי לקליטת היריון מוצלח, אולם כתוצאה מכך גדל גם הסיכוי להריון מרובה עוברים. מטרת הפרויקט הנוכחי היא לצפות מראש לאילו עוברים הסיכוי הטוב ביותר להוביל להריון מוצלח עוד בטרם השתלתם ברחם, באמצעות ניתוח מאגר נתונים של למעלה מ-70,000 עוברים. למידע נוסף, המשיכו לקרוא כאן, או בקרו באתר מעבדת בוקסבוים ובמאגר Nanshe Database.