


by Sondra Turjeman
Quantitative Biological Research with Python – The Online Course
As you may recall, a bit over a year ago, we interviewed Prof. Michal Linial and spotlighted the Hebrew University course Quantitative Biological Research with Python. Now we are here with a few updates on the course – the big one is it’s gone digital: the course is now offered completely online. We spoke with course TA Nadav Brandes to hear how they decided to go this route, what has changed, and what participants can expect to get out of the revamped course. To learn a bit more about what is covered in the course, see our previous post of the course site.
Was this always the plan or is this a consequence of COVID-19?
Nadav and Michal had been talking about making the switch to an online course before the COVID-19 outbreak (though it did provide a bit more incentive). They firmly believe that coding is an indispensable tool for all biologists and wanted to increase access to the course. Additionally, they knew that not everyone could invest twelve weeks of intensive work like the frontal course required. Making the class open expands accessibility to an international audience and allows participants to work at their own pace. An additional consideration was that Nadav is finishing his PhD (and his TA work) this year which means the course, as we know it, would likely need to undergo some big changes if it remained frontal.
What has changed?
Not very much. The course is largely the same as it was in its original format. Participants will gain the same coding, biological, and statistical skills, and lectures and TA sessions are also more or less the same. Nadav said he put a lot of effort in documenting the little things he normally said while teaching (e.g. “this exercise is more important” or “this one is really challenging – don’t get discouraged”).
Who is the main audience? Still HUJI students?
The goal in moving this course online was to make it accessible to anyone and everyone – Hebrew University students, other university students, researchers, hobbyists, or anyone else who comes across it. Initial advertising began within the university, but after posting on the reddit bioinformatics thread, international interest grew, hitting a peak of several hundred users per day. Interaction with the site remains in the tens per day now, and interest is growing as word-of-mouth publicity continues.
What about the collaborative nature of the course?
One of the tradeoffs of moving the course online is that it loses some of the collaborative interactions we fostered in the frontal course. There are forums dedicated to general discussions as well as each of the topics, and Nadav will be actively monitoring them, offering support and wisdom when needed. As participation grows, the hope is that student interactions and collaborations will continue to blossom in the digital format as well.
Are assignments graded?
This is an open course – there is no enrollment, no progress tracking, and not set of obligations. It is offered as a tool to allow participants to hone their quantitative research skills. As such, they are encouraged to wrestle with coding challenges at their own pace. The only grade they receive is the successful implementation of their code. There is a detailed answer guide as well for tips on how to tidy up code and increase efficiency.
Do the modules build off one another or can researchers just focus on topics of interest to them?
While the modules do connect to one another, they do not necessarily have to be completed in order. Everything is a function of a participant’s prior coding experience and his biological and statistical knowledge base. The recommendation is to go from beginning to end, but by moving to an online, open format, there really aren’t too many rules.
We wish everyone good luck as they make their way through this awesome learning opportunity!


Infer, filter and enhance topological signals in single-cell data using spectral template matching
Single-cell RNA sequencing is a powerful technology that allows researchers to analyze gene expression in individual cells, providing insights into cellular processes and functions. However, analyzing this data can be challenging, as cells can simultaneously encode multiple, potentially cross-interfering, biological signals. A new computational method, scPrisma, was developed to address this challenge. scPrisma has the ability to uncover cellular spatiotemporal context and has the potential to drive further insights into cellular processes and functions, ultimately advancing our understanding of biology.

התנהגות שיחור מזון חברתית – מעבדת האקולוגיה של התנועה של פרופ' רן נתן
עטלף הפירות המצרי משחק תפקיד מפתח בהפצת זרעים של מגוון צמחים, לרבות מינים פולשניים. עטלפי פירות ידועים בתור מין חברתי ביותר, אולם דפוסי שיחור המזון שלהם נותרו עד היום בגדר תעלומה, וכך גם ההתנהגויות החברתיות הנלוות לאותם דפוסים. חוקרים מקווים לשנות את כל זה באמצעות שימוש במכשירים איתור-מיקום ממוזערים ברזולוציה גובהה, שהוצמדו לאוכלוסיית עטלפים גדולה (כמעט מושבה שלמה) לצורך איסוף נתונים מדויקים על הרגלי התעופה, ההפצה והניווט שלהם. ניתוח הנתונים בראי תורת הגרפים יאפשר, כך מאמינים החוקרים, לחשוף את הרשת החברתית הפועלת מאחורי ההתנהגות המסתורית של העטלפים ולהגיע לתובנות משמעותיות שלא היו נגישות עד כה. כדי לדעת עוד, המשיכו לקרוא או בקרו באתר המעבדה ל אקולוגיה של התנועה (אנגלית).
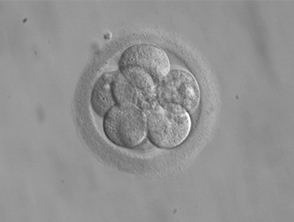
הפריה חוץ־גופית: הערכת איכות עוברים לפני החזרתם לרחם – מעבדת בוקסבוים למכאנוביולוגיה תאית וביופיסיקה של תאי גזע וגרעינים
לפחות אחד מתוך 25 תינוקות בישראל הוא תינוק מבחנה, אך עדיין אין ברשותנו אמצעים מדויקים להערכת איכות העובר טרם השתלת הביצית המופרית ברחם. לכן, מקובל להשתיל מספר עוברים על מנת להגדיל את סיכויי לקליטת היריון מוצלח, אולם כתוצאה מכך גדל גם הסיכוי להריון מרובה עוברים. מטרת הפרויקט הנוכחי היא לצפות מראש לאילו עוברים הסיכוי הטוב ביותר להוביל להריון מוצלח עוד בטרם השתלתם ברחם, באמצעות ניתוח מאגר נתונים של למעלה מ-70,000 עוברים. למידע נוסף, המשיכו לקרוא כאן, או בקרו באתר מעבדת בוקסבוים ובמאגר Nanshe Database.