


by Sondra Turjeman
The Center for Interdisciplinary Data Science Research (CIDR) has received numerous applications for collaboration from researchers and students with fields of study as diverse as cognitive science, astrophysics, journalism, and nanomaterials. Four collaborative projects have already been brought to completion, and ten collaborations are currently being supported by CIDR with the help of its six data scientists. Additional collaborations are in the pipeline and the Center continues to receive inquiries. But what does it actually mean to be work with our team? I sat down with Yuli Slavutsky, one of the Center’s mentors, to get a better understanding of what CIDR can do for you, whether you are a faculty member or a PhD student. If you are looking to integrate data science tools into your research, read on.
Yuli shares an office with David Freud, another leading Center mentor, in the new CIDR Center complex in the Rothberg C Building. Yuli learned about the Center after taking one of our co-founder, Dr. Yuval Benjamini’s classes (she is now a PhD student in his lab), and she and David, who came to the Center through Prof. Dafna Shahaf, the Center’s second co-founder, both have a background in statistics, computer science and big data, and enjoy teaching and collaborating with others in the very limited free time they have.
Here is how it works: researchers submit requests to collaborate here, and all inquiries are then automatically routed to the Center GitHub managed by the Center’s project coordinator and data scientist Yoni Levi. From there, Yoni, Yuli, David, and the other data scientists divide up the projects based on personal interest and reach out to the researchers. If it seems like a collaboration is viable and both the Center mentor and the researcher are able to commit to working together (not in an outsourcing model but in a truly collaborative manner), then a match is made and the team gets to work.
Yuli told me about her work with master’s student Eitan Margulis from Prof. Masha Niv’s lab on the perception of bitter taste. There are over 1,000 chemically diverse compounds that elicit bitter taste in human and rodents. Those compounds are recognized by distinct receptors, called bitter taste receptors that are also very different from one another (in humans there are 25 subtypes). Some receptors are activated by many bitter ligands (molecules that elicit cell response to outer stimuli by activating receptors) and some by only one or two known ligands. It is hard to study these ligands and receptors, though, because only a few ligand-receptor pairs have been directly tested, and scientists are still largely unsure which receptors bind which ligands. Thus Prof. Niv’s lab has set out to resolve this mystery. They are combining extensive literature review with lab experiments and advanced chemoinformatic and bioinformatic methods towards the goal of developing a machine learning algorithms to predict bitterness of ligands. In order to predict which receptor binds a given ligand, they approached the Center for research support in the form of a CIDR collaboration.
Before most researchers start a project, they spend a lot of time reading up on their research topic and collecting data, but Yuli and her fellow data scientists start in the middle, getting a crash course from their collaborators. Then they dive into the data. Before they can begin analyzing, it is essential that they understand how the data is structured and if there are any dependencies. For example, it is important to understand if missing values in datasets are unknown because they have never been tested or because experiments failed. Only then can they jump into their projects.
In the bitter taste project, Yuli received a matrix including rows of ligands and columns of receptors. For each ligand-receptor pair, Eitan indicated whether the ligand could bind with the receptor. The matrix was populated with data from previously published studies as well as experiments that Eitan and his lab mates performed. Despite huge efforts on Eitan’s part though, there were still a lot of blanks because there are just too many ligand-receptor pairs to test.
This is where Yuli came in. When Eitan and Prof. Niv first approached the Center, they wanted help developing a collaborative filtering algorithm that exploited similarities between known and novel pairs of ligands and receptors. They also wanted to incorporate known chemical properties of the ligands and receptors in their approach. After meeting with Eitan and exploring the data, Yuli and Eitan, together with Dr. Benjamini and Prof. Niv, discussed some of the limitations of collaborative filtering, and together the team was able to evolve the research approach into something more encompassing. Yuli suggested combining standard prediction algorithms that build off of the known chemical properties Eitan and Prof. Niv wanted to include with the original idea of collaborative filtering. To this end, Eitan went back to the lab to calculate the ligand and receptor chemical properties that Yuli needed as inputs for the algorithm by applying chemoinformatic tools to explore 2D and 3D properties of the ligands as well as bioinformatic tools to collect structural data regarding receptors and their binding sites (both from the protein sequences and the 3D models of the receptors that were generated in the Niv Lab). Yuli incorporated this new data in the algorithm, and together they determined what other information could improve its predictive accuracy. Then Eitan continued in the lab and combing through the literature. Through this process, Yuli and Eitan worked tightly together, collecting data and updating their algorithm until they were satisfied with its performance. Eitan and Prof. Niv were involved from the get-go, making sure they understood how the algorithm that Yuli developed worked, and Yuli was involved as an equal partner, helping to guide data collection efforts to ensure that together, they could best answer their research question.
Collaborations with the Center fulfill a variety of needs: Sometimes researchers need help with data cleaning, other times support in the analysis stage is needed. In cases like Yuli and EItan’s, an enduring collaborative relationship was born, and Yuli worked with her collaborators not just on complex code but on the creative brainstorming of how to best answer the research question at hand. In some projects, researchers want to be involved in the development and coding processes, and others are happy to develop the analysis pipeline and then receive a working tool without understanding all of its nuances. Yuli, David, Yoni, and the other CIDR mentors are happy to fill whatever role their collaborators need; the only requirements for a collaboration are having a research topic led by a graduate student or post-doctoral fellow, eagerness to learn – whether it be a new analysis or learning to code – and the commitment to active collaboration. CIDR mentors are not coders-on-demand but rather data-scientists who want to work with you to reach your full potential as a researcher while producing sound science.
Yuli’s work with Eitan is ongoing. Check back here in a few months for an update on what they found. In the meantime, for those interested in initiating a collaboration with CIDR, fill out the collaboration request form here. Good luck!

Infer, filter and enhance topological signals in single-cell data using spectral template matching
Single-cell RNA sequencing is a powerful technology that allows researchers to analyze gene expression in individual cells, providing insights into cellular processes and functions. However, analyzing this data can be challenging, as cells can simultaneously encode multiple, potentially cross-interfering, biological signals. A new computational method, scPrisma, was developed to address this challenge. scPrisma has the ability to uncover cellular spatiotemporal context and has the potential to drive further insights into cellular processes and functions, ultimately advancing our understanding of biology.

התנהגות שיחור מזון חברתית – מעבדת האקולוגיה של התנועה של פרופ' רן נתן
עטלף הפירות המצרי משחק תפקיד מפתח בהפצת זרעים של מגוון צמחים, לרבות מינים פולשניים. עטלפי פירות ידועים בתור מין חברתי ביותר, אולם דפוסי שיחור המזון שלהם נותרו עד היום בגדר תעלומה, וכך גם ההתנהגויות החברתיות הנלוות לאותם דפוסים. חוקרים מקווים לשנות את כל זה באמצעות שימוש במכשירים איתור-מיקום ממוזערים ברזולוציה גובהה, שהוצמדו לאוכלוסיית עטלפים גדולה (כמעט מושבה שלמה) לצורך איסוף נתונים מדויקים על הרגלי התעופה, ההפצה והניווט שלהם. ניתוח הנתונים בראי תורת הגרפים יאפשר, כך מאמינים החוקרים, לחשוף את הרשת החברתית הפועלת מאחורי ההתנהגות המסתורית של העטלפים ולהגיע לתובנות משמעותיות שלא היו נגישות עד כה. כדי לדעת עוד, המשיכו לקרוא או בקרו באתר המעבדה ל אקולוגיה של התנועה (אנגלית).
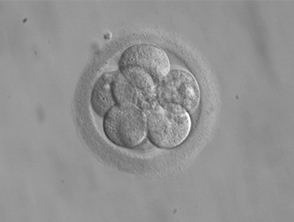
הפריה חוץ־גופית: הערכת איכות עוברים לפני החזרתם לרחם – מעבדת בוקסבוים למכאנוביולוגיה תאית וביופיסיקה של תאי גזע וגרעינים
לפחות אחד מתוך 25 תינוקות בישראל הוא תינוק מבחנה, אך עדיין אין ברשותנו אמצעים מדויקים להערכת איכות העובר טרם השתלת הביצית המופרית ברחם. לכן, מקובל להשתיל מספר עוברים על מנת להגדיל את סיכויי לקליטת היריון מוצלח, אולם כתוצאה מכך גדל גם הסיכוי להריון מרובה עוברים. מטרת הפרויקט הנוכחי היא לצפות מראש לאילו עוברים הסיכוי הטוב ביותר להוביל להריון מוצלח עוד בטרם השתלתם ברחם, באמצעות ניתוח מאגר נתונים של למעלה מ-70,000 עוברים. למידע נוסף, המשיכו לקרוא כאן, או בקרו באתר מעבדת בוקסבוים ובמאגר Nanshe Database.