


אחרי שנים של קריאה צמודה בתמלילי עדויות מפשעי זוועה המוניים ד”ר רננה קידר מצאה את עצמה תוהה: למה להסתפק בניתוח של כמה מאות קטעי שמע, בעידן בו מחשב יכול “להקשיב” לכל הקורבנות? יחד עם ד”ר עמרי אבנד ופרופ’ עמית פינצ’בסקי, ובתמיכה של מענק CIDR, הם הולכים לפתח אלגוריתם שיידע להאזין לכמות אדירה של עדויות שואה, בתקווה לפתוח אופק מחקרי ומשפטי חדש.
מאת צליל שרון
ד”ר רננה קידר, חברת הסגל הראשונה באוניברסיטה העברית שגויסה לתחום מדעי הרוח הדיגיטליים, היא חיה מעניינת בנוף האקדמי. דרך פיוטית לתאר אותה תהיה לומר שלבה בעולם הרוח של הספרות, ראשה בפרוצדורות חישוביות ורגליה נעוצות חזק בקרקע המשפטית. כשהיא מציגה את המחקר שלה בפני קהלים שונים, גבות רבות מתרוממות. “מצד אחד, אנשי ספרות מתרגשים מהאפשרות לפתוח אופק הרמנויטי חדש לחלוטין באמצעות כלים חישוביים; מצד שני, אנשי כלכלה ומשפטים, בעיקר אלה שעוסקים בצד האמפירי של המשפט, אומרים לי: ‘אבל מה עשית פה? בסוף את תמיד מכניסה את הפרשנות שלך’. ואני עונה, ברור שבסוף אני מכניסה את הפרשנות שלי, מה זאת אומרת? יש לכם תחושה שאתם חיים מחוץ לפרשנות שלכם?”.
מצוידת בגישה הלא-מסורתית הזו היא חברה לד”ר עמרי אבנד מהחוג למדעי הקוגניציה בביה״ס למדעי המחשב ולפרופ’ עמית פינצ’בסקי מהמחלקה לתקשורת באוניברסיטה העברית, במטרה לבנות יחד אלגוריתם ראשון מסוגו: כלי שיידע “להאזין” לכמות חסרת תקדים של עדויות השואה ולחלץ מהן בצורה שיטתית סכמות נרטיביות משותפות, דפוסים ומבנים. אם הם יצליחו, הכלי שלהם יוכל לזהות גם חריגה מאותם דפוסים: חשבו למשל על אפשרות לזהות טראומה או אלימות מינית מבלי לערב את האוזן האנושית בתהליך הפקת המשמעות המורכב – מעשית ורגשית – שכרוך בהאזנה לאינספור עדויות. ניתוח המבנה הנרטיבי, כך מאמינים החוקרים, יוכל לחשוף בפנינו תובנות שלא היו נגישות לנו עד כה, שלא לדבר על המהפכה שהוא עשוי לחולל בתחום המשפט. בזכות מקוריותה, לצד היבטים נוספים, זכתה הצעת המחקר שלהם במענק של מרכז CIDR לשיתוף פעולה בין חוקרי מדע נתונים לחוקרים מתחומים אחרים, וכעת הפרויקט נמצא בשלבי פיתוח ראשונים. ד”ר קידר , העומדת בראשו, התיישבה לספר לנו למה היא חושבת שהמתח בין הטקסט למספרים חיוני להנעת מחקרים פורצי דרך ואיך מלמדים מכונה להאזין לסיפורים אנושיים.
לפני הכול, אפשר להבין איך אלגוריתם יכול “להאזין” לעדויות? הרי הוא לא יודע “לקרוא” את הנתונים האלה כמו שאני ואת קוראות טקסטים או מקשיבות להקלטה.
“נכון, זאת לא קריאה או הקשבה במובן שאנחנו רגילים אליו. זו קריאה מהסוג שחושף ממדים אחרים. לכן הדבר הראשון שצריך להגיד לכל החושדים וגם למהללים הוא שהתהליך הזה אף פעם לא בא לבד, הוא תמיד משלים את הקריאה הצמודה שאנחנו עושים במדעי הרוח והחברה – קריאה של טקסט אחד – שעוסקת בשאלות כגון: למה התכוון המשורר? מה פירוש פסק הדין הזה? הרעיון הוא לקחת את האינטואיציות המחקריות שדרכן הסתכלנו עד היום על העולם, כלומר דרך כמה עשרות או מאות אובייקטים, ולנסות להסתכל דרך 4 מיליון אובייקטים. אני רואה את זה כמשחק של היזון חוזר, משום שהאלגוריתם מאפשר לנו טווח משחק רחב בין זום-אין וזום-אאוט על הקורפוס; זה לא שאיבדתי עכשיו את המסמכים שלי לאיזה קורפוס אדיר וחסר אחיזה.”
את יכולה לנסות לתאר לנו איך נראה התהליך הזה מנקודת המבט של האלגוריתם? מה האלגוריתם “מבין” לגבי הטקסט שהחוקר לא יכול לזהות בעצמו?
“אני בעצם לוקחת את כל הקורפוס של העדויות ומזינה אותן למחשב. המחשב לגמרי אגנוסטי אליהן, אין לו מושג מה זה אומר. האלגוריתם שאני עובדת איתו הוא unsupervised (בלתי-מפוקח), זה לא כמו ניתוח סנטימנטים שבו האלגוריתם מבוסס על דירוג של מילים רלוונטיות במילון. למחשב במקרה שלי אין שום מושג שמדובר בשואה, הוא לא יודע כלום. הוא פועל על בסיס תהליך גנרטיבי סטטיסטי שממיין את המילים לסלי-נושאים. הוא בעצם אומר: אלה המילים שעל בסיס הניתוח הסטטיסטי שלי אני מזהה שהן בסבירות הגבוהה ביותר לבוא יחד באותו מסמך. אם לדוגמה נכניס את כל ארכיון הארץ לאלגוריתם הזה ונגיד לו ‘תן לי עשרה נושאים’ – אנחנו קובעים את מספר הנושאים בשביל האלגוריתם וזו בעצם ההתערבות הישירה היחידה שלנו כחוקרים (כמה שווה ה-k) – רוב הסיכויים שנקבל אוסף מילים שמתקשר, למשל, לפוליטיקה. הוא יכלול מילים כמו ‘נתניהו’, ‘שרים’, ‘ממשלה’, ‘בחירות’; יהיה אשכול נוסף בנושא צבא, עם מילים כמו ‘קטיושות’, ‘קאסמים’, צבע אדום’, וכן הלאה.”
את השיטה הזו, המכונה topic modeling, מבקשת רננה ליישם עם עמיתיה על מאגר עדויות שואה עצום בגודלו. עד כה התנסתה בה בהצלחה בפרויקט העוסק בניתוח עדויות ממשפט אייכמן.
“יוצאים לי נושאים מאוד מובחנים”, היא מעידה, “למשל מילים שקשורות לפרוצדורת בית המשפט כמו ‘נאשם’, ‘שאלה’, ‘חקירה’, ‘כבודו’, יוצאות לי מילים שקשורות לגטו… בקלאסטר אחר מילים שקשורים ל’הונגריה’, כי במשפט אייכמן היה פרק מאוד גדול על שואת יהודי הונגריה. מן הסתם, האלגוריתם לא יודע כלום על שואת יהודי הונגריה או על שואה בכלל, אבל הוא מזהה שהמילים האלה באות ביחד. עכשיו לגבי כל מסמך בטקסט יש לי את ההרכב הנושאי שלו ואני יכולה לחזור ולבחון האם בטקסטים שעד היום קראתי רק בקריאה צמודה באמת עולים הנושאים האלה. אז יש כאן כל הזמן משחק בין רמת המעלה למטה וזה מה שמרתק בעיני.”
***
“אנחנו לא אמורים להקשיב לנשים שעברו את הזוועות האלה עם אלגוריתם ממוחשב, אבל אם לא נכניס כאן את האלגוריתם לא נקשיב להן בכלל”
כמי שעברה מסלול פתלתל בין דיסציפלינות שונות שהביאו אותה עד הלום, על השאלה “כיצד את מציגה את עצמך?” – אין לה תשובה חד משמעית. “נתחיל מזה שאני לא מגדירה את עצמי כמדענית נתונים בכלל”, היא מחייכת. את התואר הראשון שלה השלימה רננה באוניברסיטת תל אביב בחוגים למשפטים ומדעי המדינה. לאחר מכן שימשה כפרקליטה במחלקת הבג”צים בפרקליטות המדינה, כשברקע הייתה לה בכלל פנטזיה ללמוד ספרות.
רננה: “התחלתי תואר שני בספרות באוניברסיטת תל אביב סביב לידת הילד הראשון שלי ואז הגעתי לסטנפורד דרך התגלגלות נסיבות אישיות. התקבלתי שם לדוקטורט במשפטים וגם בספרות, ובסוף החלטתי ללכת לדוקטורט בספרות השוואתית בנושא השינויים שחלו בתפיסות צדק בעקבות פשעי זוועה המוניים. בעצם כל עבודת הדוקטורט שלי הייתה חיבור בין משפטים וספרות, תחום אנלוגי לגמרי”.
נקודת המפנה בה נרקם החיבור שלה עם עולם מדע הנתונים התרחש בעקבות מפגש עם כתביו של פרנקו מורטי, שטבע את המושג קריאה מרחוק (distant reading). “פרנקו מורטי הוא אחד מחוקרי הספרות הכי חשובים בעולם”, היא מסבירה, “הוא חקר את הרומן האירופאי והיה הכי מסורתי שאפשר במחקר הספרותי, אבל אז בסביבות שנת 2000 הוא ממציא את המושג הזה, שאומר, מאוד בהפשטה: למה לקרוא רק את ה-1000 או ה-3000 ספרים שאנחנו קוראים, כשאפשר לקרוא הכול?”
אבל אי אפשר לקרוא הכול. אני לא בטוחה שנצליח לקרוא הכול גם אם כל אדם בעולם יקרא ספר אחד ביום.
“בדיוק. ולכן מורטי אמר: אנחנו לא נקרא הכול בעצמנו, נקרא את זה על ידי האלגוריתם. זאת הייתה סוג של מהפכה, שדרכה נחשפתי לתחום של ניתוח טקסט חישובי (computational text analysis). היום אני מתעסקת בו מזווית של מדעי הרוח הדיגיטליים ואני מגדירה את עצמי כהומאניסטית דיגיטלית שמפנה את הזרקור שלה לא לספרות אלא למשפט. החיבור בין ספרות למשפט קיים אצלי כל הזמן ומה שאני בעצם עושה זה להבין איך שומעים נרטיבים, איך שופט שומע את הסיפורים שמספרים לו העדים.”
למה כל כך חשוב לך להבין איך שופט שומע סיפורי עדים?
“התחום שאני מתעסקת בו הוא פשעי זוועה המוניים ואחד הדברים ששמתי לב אליהם מהעבודה האנלוגית שלי הוא שיש המון עדים במשפטים האלה. זה אומר שיש לנו המון המון סיפורים. לא פשוט להקשיב לכל הקולות האלה. שופט הוא רק אדם אחד, אז גם אם יש שלושה… איך אתה מקשיב במשך שלושה חודשים לעוד אישה שנאנסה כפשע מלחמה, כשמדובר במחנות אונס המוניים בסרביה? אז איפשהו בין השאלה של הסיפור האנושי – כי אני באה מספרות – לבין השאלה של שיקול הדעת השיפוטי – נוצר מתח מעניין. איך השופט, שצריך לקבל החלטה שיפוטית של אשם או לא אשם לגבי אדם אחד, מקבל החלטות כאלה אל מול כל כך הרבה עדויות? איך מתמודדים עם עושר השיח הזה, שאנחנו לא רוצים שילך לאיבוד? כי יש פה גם רצון לכבד את העדים, לאפשר לכל הקורבנות לדבר, להשמיע את קולם. כאן בעצם נכנס האלגוריתם. את בטח שואלת את עצמך מה פתאום אלגוריתם, אנחנו לא אמורים להקשיב לנשים שעברו את הזוועות האלה עם אלגוריתם ממוחשב, אבל הטענה שלי הייתה שאם לא נכניס כאן את האלגוריתם לא נקשיב להן בכלל.”
זאת אומרת שיש כאן איזה אופק מוסרי, אתי, לגישת המחקר הזאת.
“כל הזמן. העבודה שלי כולה מבוססת על אתיקה של הקשבה, רק שבניגוד לאתיקת ההקשבה של לוינס, כאן אין לנו את הפריווילגיה להקשיב אחד על אחד. אז אם נחזור לעולם מדע הנתונים, המשמעות היא להסתכל על כל העדויות האלה כ-data sets. זה מאגר נתונים של טקסט שאני מנתחת בעזרת אלגוריתמים של עיבוד שפה טבעית.”
אבל רגע. אם האלגוריתם הולך לנתח מאגר של טקסטים, תמלילים של עדויות, למה את קוראת לזה “הקשבה” ולא “קריאה” מרחוק?
“בסופו של דבר אני מודה, אני לא מקשיבה לעדויות. העולם המשפטי עובד בעיקר על אנגלית וכל בתי המשפט הבינלאומיים קוראים עדויות בתרגום. אז תמיד אומרים לי, ‘אבל את לא באמת מקשיבה להם’ – זה נכון, אבל ככה השופטים שומעים את הקורבנות. השופטים לא מדברים סרבית או קרואטית, הם פשוט מקשיבים לתרגום לאנגלית. אומנם כחוקרת ספרת אני מאמינה מאוד בלדעת את שפת המחקר שלך, את האובייקט שאתה חוקר, אבל דווקא בגלל שמעניין אותי להבין איך השופט שומע – אני בסדר עם זה. הרי השופט שומע את העדים בתרגום סימולטני לאנגלית, עם כל המגבלות שכרוכות בזה, ומפה מגיע המושג “האזנה מרחוק”. אומנם המודל שלי הוא של שפה כתובה אבל מה שמעניין אותי זה בעצם הקשב השיפוטי, היכולת של הקורבן להיות מוכל על ידי המערכת המשפטית.”
כשרננה מדברת על “הכלה” של הקרבנות על ידי המערכת, היא עוצרת לרגע כדי לחדד את דבריה. מיומנת באתגר התיווך בין שפת מדעי המחשב לשפת מדעי הרוח והחברה, היא חובשת את כובע המתורגמנית האינטרדיסציפלינרית שלה ומסבירה: “ברור שהאלגוריתם לא בהכרח ייתן יותר אמפטיה לקורבן, אבל יש פה איזושהי מחשבה שאומרת שלפחות המידע הזה לא ירד לטמיון. שלא יישאר בצורה פרגמנטרית כזאת, בתור 500 נשים נאנסו, שיישאר לנו הסיפור”.
למה את מתכוונת, “שיישאר הסיפור”?
“שאיפשהו בעולם נדע שנשאר הסיפור הזה של האישה הספציפית הזאת, שבאה ודיברה בבית המשפט. גם אם השופט לקח מזה בסוף רק משפט אחד, אפילו אם הוא לא האמין לה או שהיא לא הצליחה להוכיח את הטענות שלה ברמה המשפטית… את יודעת, משפט זה עולם מאוד אכזרי. צריך לזכור באיזה יום ובאיזו שעה קרה מה שקרה, ומה הוא לבש ומה היו הדרגות שלו. איך מי שנאנסה על ידי עשרות אנשים במשך כמה חודשים אמורה לזכור פרטים כאלה? אבל אני עדיין רוצה לשמר את הסיפור שלה. אז במובן הזה זאת הקשבה, ולכן התעקשתי מאוד על המילה “הקשבה”, כפרפרזה על פרנקו מורטי. מורטי לא הקשיב, הוא קרא ספרים עם אלגוריתם. אני רוצה להקשיב”.
***
“זה שאתה מדען של מספרים לא משחרר אותך מהחובה לחשוב מה המספר הזה אומר”
תחום ה-Digital humanities, מדעי הרוח הדיגיטליים, עדיין נמצא בחיתוליו באוניברסיטה העברית. רננה נבחרה להוביל אותו לאחר ששימשה כעמיתת פוסט-דוקטורט במרכז מינרבה לזכויות אדם בפקולטה למשפטים, ובתכנית עמיתי בובר במדעי הרוח והחברה. היא מודה שבשנים האחרונות הפך תחום “Digital humanities” לתווית טרנדית משהו, שמכסה מגוון מחקרים בכל מיני נושאים ושיטות מחקר, שאף אחד לא בטוח איך מגדירים אותו (“כשאני התקבלתי כסגל למדעי הרוח הדיגיטליים באוניברסיטה, אחד הדברים שהכי הפחידו אותי הוא לדעת שמדעי הרוח הדיגיטליים זה הרבה מאוד דברים”, היא צוחקת). ובכל זאת, לראייתה אפשר לתחום את מדעי הרוח הדיגיטליים תחת ההגדרה הבאה: שימוש בשיטות חישוביות כדי לחקור את האובייקט ההומניסטי. דוגמה טובה לכך היא מוצאת בחוג לארכיאולוגיה.
רננה: “בארכיאולוגיה באוניברסיטה העברית יש את פרופ’ ליאור גרוסמן, שהיא גם סגנית הדיקן לענייני מחקר במדעי הרוח וגם מי הקימה את המעבדה לארכיאולוגיה חישובית. היא אחד הגורמים הכי מתוחכמים בחשיבה על חקירת האובייקט ההומניסטי דרך כלים חישוביים, דרך סריקות תלת ממדיות ושחזור אובייקט במחשב. כביכול בין זה לבין מה שאני עושה בקריאת טקסטים – שזה מה שאני עושה – אין שום קשר. אבל אם מרימים את זה לרמת הפשטה אז ברור יש לנו המון במשותף. אנחנו חולקות את המחשבה שאומרת: רגע, יש דרך אחרת לגמרי להסתכל על העולם ההומניסטי ועל איך שחקרנו אותו.”
אילו אתגרים את מוצאת במפגש שבין מדעי הרוח לעולם החישובי?
“אני עובדת עם אנשים ממדעי המחשב והרבה הולך לאיבוד ב”תרגום”. אני צריכה להסביר להם, לדוגמה, שלא מעניין אותי שבחירה של 100 נושאים זה יותר נכון מבחינה חישובית כי זה לא ייתן לי תוצאות פרשניות. אני לא בנתונים, אני בסיפור, בנרטיב.”
אפרופו נרטיב, בהצעת המחקר שלך עם ד”ר עמרי אבנד ופרופ’ עמית פינצ’בסקי, שזכתה במענק של CIDR, אתם מדברים על “ניתוח רצף נרטיבי” (sequential narrative analysis). מה זה אומר?
“החזון הוא אלגוריתם שעובר ו”מקשיב” סיפור אחרי סיפור – כשבכל עדות הוא יבנה לנו מודל למידה, כמו למידת המכונה של גוגל תמונות. מה עושה גוגל תמונות? את מראה לו אלפי תמונות של כלב ואומרת לו “זה כלב, זה כלב, זה כלב”, אחרי זה את מראה לו אלפי תמונות של חתול ואומרת לו “זה חתול, זה חתול, זה חתול”, וכשתראי לו את התמונה ה-1001 הוא כבר יידע לזהות אם זה כלב או חתול. אז אנחנו הלכנו עם אותה מחשבה לעדויות. אמרנו, בואו נראה לו [לאלגוריתם] הרבה טקסטים ונלמד אותו – “זו עדות שואה, זו עדות שואה, גם זו עדות שואה, זאת עדות שואה על ילדים, זאת עדות שואה של גבר מבוגר”, כל מיני תיוגים כאלה. עוד לא עשינו את זה, זה הכול בדמיון. העבודה בשנה הראשונה של המחקר בעצם תוקדש לקיטלוג ידני שנעשה עם עוזרי מחקר. מה שמעניין אותנו הוא להבין איך בנוי הרצף הנרטיבי של סיפור שואה. לא מעניינות אותנו העובדות ההיסטוריות. לא מעניין אותי האם העד אמר שקודם הוא ברח מאושוויץ או מגטו אחר, אלא איך נשמע סיפור שואה. להבין האם יש דרך שבה אדם בטראומה יספר את הסיפור שלו.”
איך אפשר לזהות טראומה דרך מבנה נרטיבי?
“נגיד שאנחנו בונים מודל כזה של עץ, שאומר: הוא [העד] מדבר על אירוע, ואז הוא עובר לאירוע הבא ואז הוא חוזר לאירוע הקודם, ממשיך לספר, עובר לאירוע הבא – אנחנו בעצם בונים רצף לינארי של מה שהוא מספר, לא מה קרה בעולם. איך בונים את זה? צריך לחפש ביטויי זמן, ביטויי מקום, כשהעד עובר בין זמנים ושמות גוף, כשהוא אומר ‘מחר’, ‘אתמול’, כשהוא מספר על אדם נוסף – ככה אנחנו רוצים לבנות את זה. ואז להתחיל להבין האם הסיפור מסופר בצורה לינארית או לא. האם למשל אדם קודם כל מתחיל לספר את הטראומה הכי נוראית שהייתה לו, נגיד מתחיל מזה שהיה בזונדרקומנדו ושרף את הגופות, או שהוא קודם מתחיל מלספר על זה שהוא היה רעב בגטו? האם כשילד מספר, הוא מספר אחרת? האם ילד מספר קודם כל מה שקרה לו כשהיה הכי מבוגר ואז חוזר לגיל הצעיר? האם יש דרך שבה מספרים סיפור שואה? אנחנו נלמד את המכונה והיא תוכל לזהות האם מדובר בסיפור שואה או לא.
את יודעת, בסופו של דבר הרבה עדויות נראות אותו דבר. הסיפורים משתנים אבל המבנה הנרטיבי דומה – קודם ברחנו, אחר כך עשינו ככה, וכו’. הסיבה שאני אומרת את זה היא לא כי אני מזלזלת, אלא כי קראתי את כל העדויות במשפט אייכמן. אנשים נוטים לספר לינארית. מתי הם בוחרים להתחיל פתאום באירוע אחר? למשל אם הייתה שם איזו תקיפה מינית שהם מתביישים בה, כי היה איזה שיתוף פעולה שהם מתביישים בו, כי הם היו ילדים… אני לא יודעת אבל זה מה שמעניין אותנו לחקור. משם נחשוב על האפשרויות להרחיב את זה למאגרים שונים, נגיד ניצור איזה דפוס של עדות טראומה. תחשבי שבעתיד יהיה אפשר לקחת את זה, ובהתאמות הנדרשות, תוכלי למשל לראיין אישה שבאה מחברה מסורתית שבה אסור לדבר על אונס, ולהבין, רק מהדרך שבה היא מספרת את הסיפור, שהיא עברה אונס אבל היא לא יכולה להגיד לך את זה. איך נדע? כי כבר יהיה לנו מודל של איך נראה סיפור אונס “רגיל” ואני אבין שכבר יש לי כל מיני מילים וצורות נרטיביות שמתחברות לזה, שהיא משחזרת אותם בלי להגיד במפורש שהיה אונס. אין לי מושג אם זה יעבוד אבל זה מה שאני מדמיינת.”
זה אומר שתוכלו ללמד אלגוריתם לזהות אשמה? בושה?
“לא, הוא לא יידע. את זה אנחנו נזהה, הוא רק יידע לזהות את החריגה המבנית, אבל זה בעצם מה שאנחנו צריכים ממנו. אני לא צריכה שהאלגוריתם יידע לזהות אשמה.”
אז מה כן?
“תראי, מה שהיה מקובל עד היום זה לקחת עדויות שנתפסו מאיזושהי סיבה כחשובות יותר מאחרות ולנתח אותן לעומק. במשפט אייכמן לדוגמה, כולם שמים לב לאותן 8-10 עדויות: יש את העדות של קצטניק שהתעלף על דוכן העדים כשהוא דיבר על אושוויץ, ויש את העדות של אבא קובנר שדיבר על הפרטיזנים, ויש את העדות של צביה לובוטקין… לא משנה, זוועות. אבל היו שם מאה עדויות. גם אם אני מנתחת 20 מהן, עדיין יש 80 שאף אחד לא מדבר עליהן. סתם עדויות קטנות, כאלה שמזכירים מקסימום במשפט או שניים. אף אחד לא מסתכל על המכלול, וזה מה שמעניין אותי. מה קורה כשאת מקשיבה למאה עדויות שואה? אני לא מדברת עכשיו על ההקשבה של השופט אלא עלינו, כחברה. מה לומדים כשמקשיבים למאה עדויות, האם לומדים משהו חדש? זה משהו שרק האלגוריתם יכול לתת לי, כי כבני אדם אנחנו תמיד נלך למה שאנחנו מזהים כחשוב. יש לנו הטיות מובנות וזה בסדר. תמיד אני אבוא עם שאלה מחקרית ואחפש את מה שמתחבר לי לשאלה המחקרית הזאת. האלגוריתם לא מחפש את מה שמעניין אותו, הוא לא יודע מה מעניין אותו. לכן הוא נותן לי תמונה אחרת לגמרי, אבל תמיד אני אעשה עליה בסוף פרשנות. רק שהפרשנות שלי תידחה טיפה, תושהה, לשלב קצת יותר אובייקטיבי.
אז בכנות, אני לא יודעת להגיד לך אם אחרי שאקרא את כל הטקסטים האלה תהיה לי פתאום תובנה אחרת על השואה, על טראומה או על עדות; אני כן יכולה להגיד כשאני אטען את הטענות שלי על עדויות, אני ארגיש קצת יותר מבוססת לגביהן”.
כלומר, המכונה לא הולכת לייתר את החוקר האנושי. את טוענת שהקריאה האנושית עדיין חשובה כאמצעי ניתוח משלים, חיוני אפילו.
“כן. אני חושבת שהעובדה שהגעתי מעולם הספרות השאירה אותי מאוד מחוברת למקום שממנו באתי, לטקסט, למילים. הסיבה שאני הולכת בכלל לעולם של כריית נתונים היא כי היה נראה לי שאפשר לרתום אותו כדי לחזור לטקסטים. יש מי שמעניין אותם להבין רק את הדפוסים; לדוגמה, מה המגמות של החלטות בית המשפט האמריקאי ב-60 שנה האחרונות. חוקרים כאלה לא יראו טעם לחזור לטקסט, הם יישארו ברמת הנושאים ואז יעשו ניתוחים סטטיסטיים כדי לבחון מה השונות בין השנים השונות בנושאים – וזה בסדר גמור, אבל זאת לא המטרה שלי. מה שמעניין אותי בסופו של דבר הם לא הנתונים אלא הסיפור, הנתונים מאפשרים לי לחשוף מחדש את הסיפור שקצת הלך לנו לאיבוד. אז במובן הזה אני שומרת על הגישות ההומניסטיות שלי.”
הזכרת בהתחלה את ההתלהבות מצד חוקרי הספרות, שנפתח בפניהם עולם חדש של שאלות בזכות כלים חישוביים. מה לדעתך יכולים אנשי מדעי הרוח, מהצד השני, להביא למדעני נתונים?
“זאת שאלה מצוינת, אני לא יודעת להגיד… האמת שאחרי שאני עובדת תקופה עם אנשי מדעי המחשב, אנשים שאני מאוד מעריכה כי יש להם ידע שאין לי, ברור לי שגם להם חסר הרבה מאוד– לא רק ידע, צורת חשיבה. תראי לדוגמה את סטנפורד. זאת אוניברסיטה שמחוברת בטבורה לעמק הסילקון וזה נפלא. יש שם כסף, סטודנטים מדהימים, רוח חדשנות, כל מי שנכנס לשם רק רוצה סטארט אפ. ואז 20 שנה אחרי יש לך חברות שלמות ששולטות בכל פינה בחיים שלנו אבל אין שם שום חשיבה ביקורתית או פילוסופית. אני לא אומרת שרק מי שלמד פילוסופיה קאנטיאנית יכול להפעיל חשיבה ביקורתית, אבל מי שלמד את זה לפחות יודע שהוא צריך, שכדאי, שהוא מרוויח מזה משהו. אני רואה את זה במפגשים שלי אפילו עם סטודנטים בתואר ראשון או שני במחשבים פה באוניברסיטה, שהם אנשים מבריקים, אבל אין להם את השפה הזאת. יש להם נתונים. אז הם יודעים לקמפל ולסמפל ולעשות כל מיני פרוצדורות מורכבות עם הנתונים, אבל לא תמיד הם יודעים לשאול: מה הנתונים האלה אומרים לי? ואני פוגשת אנשים שעובדים במקצועות שקשורים בחיי אדם, כמו ביולוגיה. צריך להבין שנתונים בכלכלה ונתונים בביולוגיה ונתונים ברפואה זה לא אותו דבר. זה שאתה מדען של מספרים לא משחרר אותך מהחובה לחשוב מה המספר הזה אומר. לכן אני חושבת שהחיבור כל כך חיוני: אנחנו צריכים גם אנשים שגם מבינים את החשיבה הביקורתית וגם יודעים לקרוא את הטקסטים הנתוניים. בעולם האידיאלי הוא עולם של אנשים שהם באמת digital humanist, שלמדו גם את מדע הנתונים וגם את מדעי הרוח בצורה אמתית ועמוקה, לא הלבישו תחום אחד על השני.”
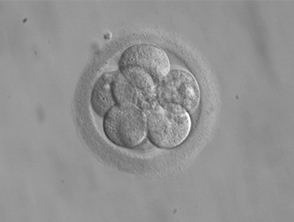
הפריה חוץ־גופית: הערכת איכות עוברים לפני החזרתם לרחם – מעבדת בוקסבוים למכאנוביולוגיה תאית וביופיסיקה של תאי גזע וגרעינים
לפחות אחד מתוך 25 תינוקות בישראל הוא תינוק מבחנה, אך עדיין אין ברשותנו אמצעים מדויקים להערכת איכות העובר טרם השתלת הביצית המופרית ברחם. לכן, מקובל להשתיל מספר עוברים על מנת להגדיל את סיכויי לקליטת היריון מוצלח, אולם כתוצאה מכך גדל גם הסיכוי להריון מרובה עוברים. מטרת הפרויקט הנוכחי היא לצפות מראש לאילו עוברים הסיכוי הטוב ביותר להוביל להריון מוצלח עוד בטרם השתלתם ברחם, באמצעות ניתוח מאגר נתונים של למעלה מ-70,000 עוברים. למידע נוסף, המשיכו לקרוא כאן, או בקרו באתר מעבדת בוקסבוים ובמאגר Nanshe Database.

התנהגות שיחור מזון חברתית – מעבדת האקולוגיה של התנועה של פרופ' רן נתן
עטלף הפירות המצרי משחק תפקיד מפתח בהפצת זרעים של מגוון צמחים, לרבות מינים פולשניים. עטלפי פירות ידועים בתור מין חברתי ביותר, אולם דפוסי שיחור המזון שלהם נותרו עד היום בגדר תעלומה, וכך גם ההתנהגויות החברתיות הנלוות לאותם דפוסים. חוקרים מקווים לשנות את כל זה באמצעות שימוש במכשירים איתור-מיקום ממוזערים ברזולוציה גובהה, שהוצמדו לאוכלוסיית עטלפים גדולה (כמעט מושבה שלמה) לצורך איסוף נתונים מדויקים על הרגלי התעופה, ההפצה והניווט שלהם. ניתוח הנתונים בראי תורת הגרפים יאפשר, כך מאמינים החוקרים, לחשוף את הרשת החברתית הפועלת מאחורי ההתנהגות המסתורית של העטלפים ולהגיע לתובנות משמעותיות שלא היו נגישות עד כה. כדי לדעת עוד, המשיכו לקרוא או בקרו באתר המעבדה ל אקולוגיה של התנועה (אנגלית).